



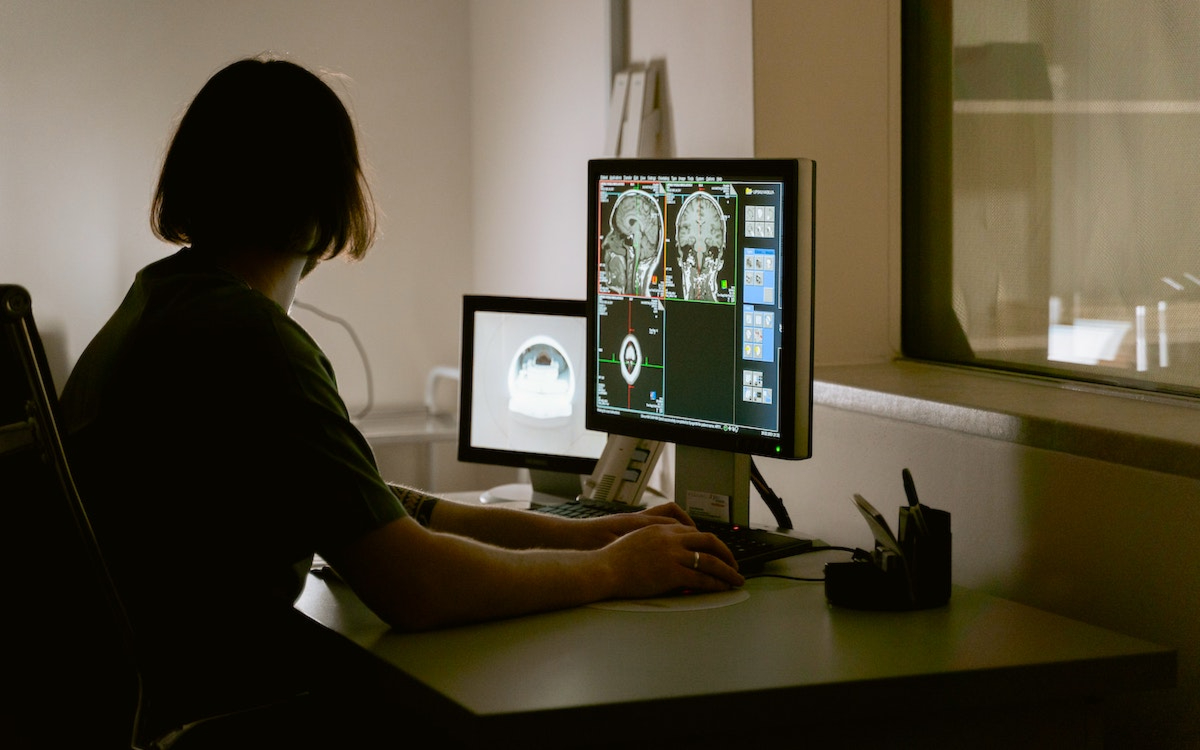
По оценкам Международного агентства по изучению рака IARC, каждый пятый человек в течение своей жизни заболевает онкологией. В 2019 году только в России было выявлено свыше 640 тыс. человек с онкозаболеваниями. Эксперты связывают рост смертности от онкологических заболеваний с общим старением населения. Шансы выжить у онкобольных зависят от того, на какой стадии обнаружен рак: чем раньше, тем лучше.
Искусственный интеллект: эволюция в диагностике рака
Искусственные нейронные сети и автоматический анализ данных используются для обнаружения и диагностики рака с середины 1980-х годов. Сегодня наиболее инновационные методы основаны на машинном обучении.
Чем отличаются машинное и глубокое обучение
Машинное обучение (Machine Learning, ML) — метод искусственного интеллекта, который используют для анализа данных. Алгоритм анализа выстраивает единую математическую модель при помощи процесса «обучения» нейронной сети, которая схожа с обучением детей.
Ребенок распознает буквы, учится складывать их в слоги, а слоги — в предложения. Процесс обучения нейронной сети также основан на исходных элементах данных, на которых сеть учится решать какую-то задачу.
Глубокое обучение (Deep Learning, DL) — разновидность машинного обучения на основе нейронных сетей. Основное отличие глубокого обучения от машинного основано на том, как данные представляются в систему. Алгоритмы машинного обучения почти всегда работают на структурированных наборах данных, а сети глубокого обучения полагаются на собственные слои ANN (искусственных нейронных сетей) для самостоятельного структурирования данных.
Ошибочность моделей как машинного, так и глубокого обучения зависит от качества данных.
Мнения о зрелости и успешности машинного обучения в медицине для анализа изображений КТ, МРТ, маммограмм и так далее для обнаружения рака разделились. Суммарное количество проектов и позитивных научных публикаций по ML-диагностике рака растет, но, например, IBM как один из первых разработчиков, который тестировал IBM Watson Oncology больше чем в 50 клиниках, в 2020 году сократил штат сотрудников подразделения, а в 2021-м объявил о намерении его продать.
Несмотря на волну скептицизма, количество разработок и продуктов для обнаружения злокачественных новообразований увеличивается, включая рекомендованные FDA (Управлением по санитарному надзору за качеством пищевых продуктов и медикаментов США). Например, лидерами скрининга рака легкого считаются Philips Healthcare и SIEMENS Healthineers. Google AI Healthcare и IBM Watson Oncology тоже популярны, хотя и не рекомендованы FDA. На рынке ML-решений существует большая конкуренция со стороны стартапов и проектов с открытым исходным кодом. На текущий момент FDA разрешили использование для медицинских целей свыше 80 ML-решений.
Примеры использования ML-решений
- Алгоритм Mia для скрининга груди английского проекта Kheiron Medical Technologies хорошо зарекомендовал себя как второе мнение. Первые результаты более чем 40 тыс. маммограмм показали, что если Мia будет использована в качестве второго рентгенолога, общий коэффициент повторения двойных чтений (процент женщин, которых вызывают для дальнейшего исследования) составит 4–5%, а уровень выявления рака — 8,4 человека на 1 тыс. пациенток.
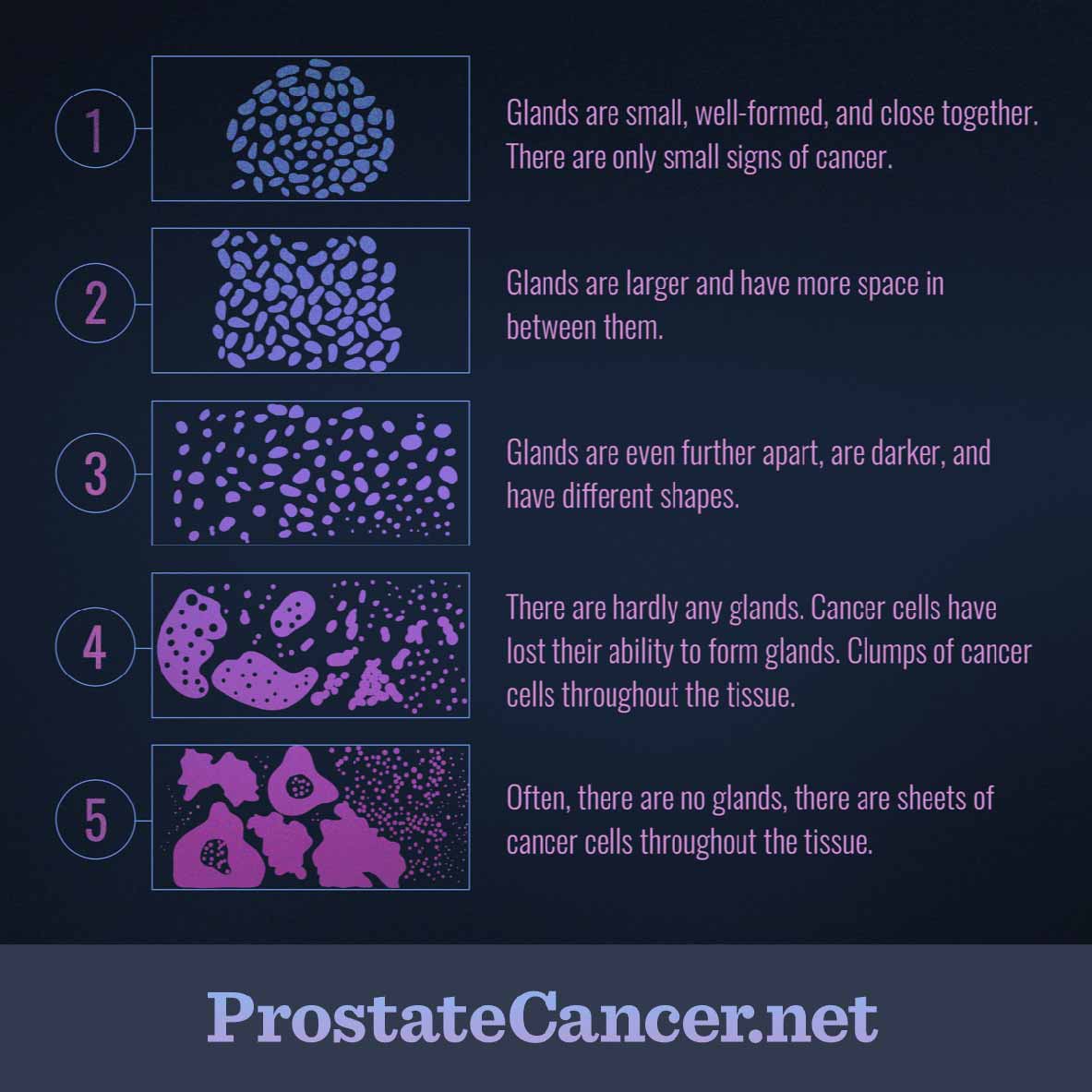
- Шкала Глисона — это популярная система оценки рака простаты, разработанная еще в 1966 году. Врачи исторически оценивали биопсию тканей визуально. И только в 2019-м Мартин Штумп (из AI and Data Science) и Крейг Мермел (из Google AI Healthcare) разработали систему глубокого обучения для шкалы Глисона. Диагностическая точность составила 0,7 (по шкале от 0,5 «случайный» до 1 «100% правильный»). Это отличный результат по сравнению с диагнозом, поставленным 29 врачами, точность которого — 0,6.
Евгений Никитин, руководитель департамента искусственного интеллекта, ООО «Медицинские скрининг системы» («Цельс»):
«Хорошие клинические показатели ML-систем не гарантируют пользы от их внедрения. В каждой конкретной задаче оптимизировать нужно свою метрику — например, время, затрачиваемое на описание одного исследования, денежные затраты пациентов и больниц, процент обнаруженных новообразований, требующих экстренной медицинской помощи. Пока полноценных историй успеха внедрения ML-систем очень мало, но первые результаты дают надежду: например, результаты наших экспериментальных испытаний показывают, что использование ML-систем ускоряет описание маммографического исследования на 30-40%. А клинические испытания нашей системы «Цельс» в ГБУЗ «Тамбовский областной онкологический клинический онкодиспансер» показали рост выявляемости онкологии на ранней стадии на 10%».
Как работает ML-диагностика рака
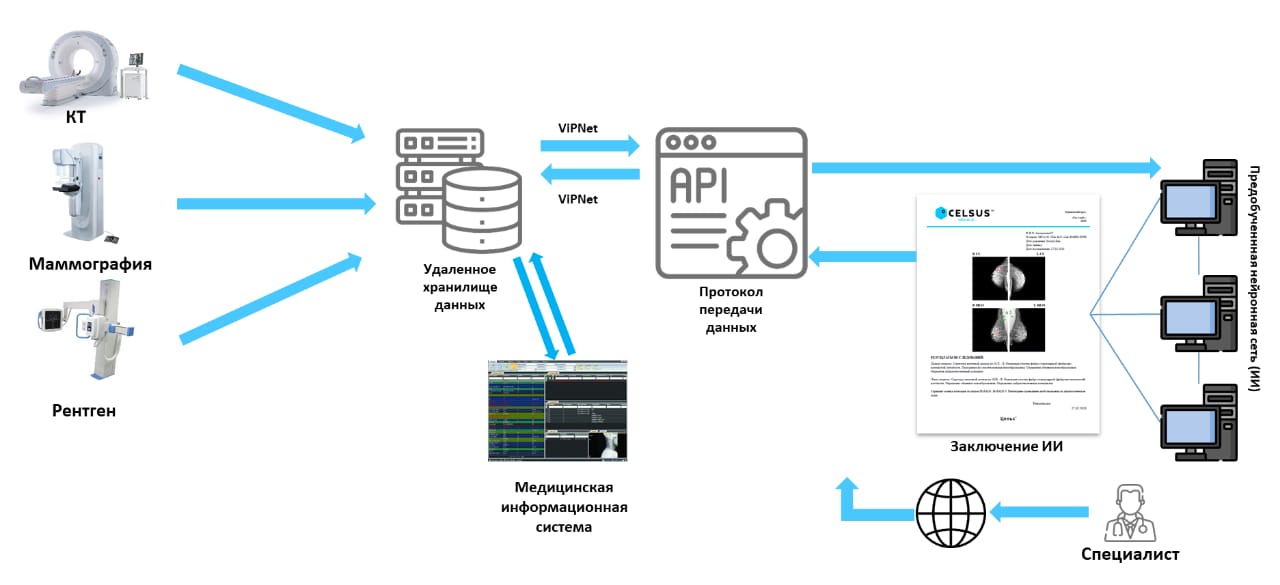
Большое количество изображений (полученных с помощью КТ, МРТ, маммографии или гистопатологии) собраны в наборы данных — датасеты, которые стали использоваться для обучения алгоритмов машинного обучения.
Изображение загружают в систему, которая распределяет список исследований по приоритетности — от наибольшей вероятности наличия патологии до наименьшей. Так врач сначала посмотрит снимки пациентов, у которых система спрогнозировала новообразование. Либо же специалист просматривает изображение, где ИИ маркером выделил зону патологии, и вносит свое замечание в описание снимка, сделанное ИИ.
Процесс создания ML-модели разработчиками состоит из многих этапов — сбор и разметка данных, предобработка изображения (например, сегментация органа и удаление лишних частей изображений), обучение нейронной сети, калибровка результатов под конкретный сценарий применения.
Одна из самых сложных стадий — сегментация (выделение признаков) для классификации на злокачественную или доброкачественную опухоль. Для распознавания и сегментации каждого типа рака используются разные процессы подготовки изображений и обучения, которые отличаются для диагностики, например, рака кожи и лейкемии.
Как тестируется ML-диагностика рака
Так как алгоритмов и датасетов много, существует проблема сравнения ML-решений, разработанных для одного и того же клинического применения.
Какие метрики используют для сравнения ML-решений
Для оценки систем машинного обучения можно использовать сотни различных показателей. Самыми простыми для понимания являются показатели на основе разбивки предсказаний ИИ-решений на четыре категории:
- Истинно Положительные (ИП) — патология действительно есть, и ML-решение ее обнаружило.
- Истинно Отрицательные (ИО) — патология отсутствует, и ИИ ничего на обнаружил.
- Ложно Положительные (ЛП) — патологии нет, но система что-то нашла.
- Ложно Отрицательные (ЛО) — патология есть, но ИИ ее пропустил.
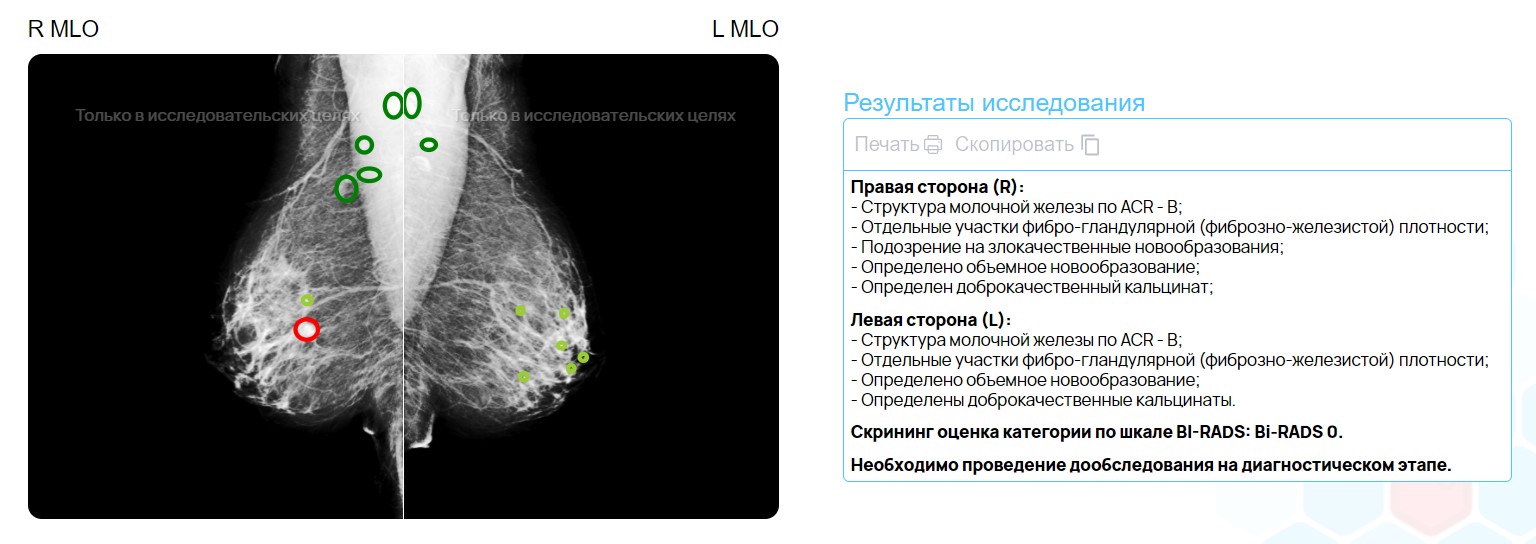
Машинное обучение сейчас активно тестируется для выявления рака мозга, груди, легкого, кожи, крови и печени. В России в 2020 году Центром диагностики и телемедицины был развернут проспективный эксперимент для тестирования ИИ-решений. Он стал самым большим научным исследованием в мире на эту тему. Алгоритмы для выявления рака молочной железы и рака легкого включили в московскую программу тестирования летом 2020 года после сервисов для диагностики COVID-19.
Наталья Ледихова, замдиректора по медицинской части Научно-практического клинического центра диагностики и телемедицинских технологий Департамента здравоохранения Москвы, рассказала РБК Трендам, что по результатам тестирования ИИ для выявления рака молочных желез время на описание исследования сокращается на 15–50%. Кроме того, алгоритмы обрабатывают медицинские снимки в режиме реального времени и приоритезируют их: первыми врачу поступают исследования, на которых с большей вероятностью обнаружены онкологические изменения. ML-сервисы акцентируют внимание врача на самых незначительных признаках патологии — это может помочь при ранней диагностике рака, особенно при больших потоках рутинных исследований, когда у специалиста может «замыливаться» взгляд. Точность и чувствительность искусственного интеллекта постоянно растет.
В 2020 году для диагностики онкологических заболеваний в России использовались разработки Philips (НДКТ органов грудной клетки, рак легкого), Botkin AI (КТ органов грудной клетки, рак легкого), «Цельс» и Lunit (маммография, рак молочной железы). В будущем онкологическое тестирование может быть расширено сервисами для выявления злокачественных опухолей головного мозга.
Перед подключением сервисов к основному контуру Единого радиологического информационного сервиса (ЕРИС), которым пользуются московские рентгенологи, ML-решения проходят внутреннюю валидацию на независимых массивах данных, собранных и структурированных Центром диагностики и телемедицины (эталонных наборах обезличенных исследований, предварительно размеченных рентгенологами) в тестовом контуре сервиса. На данный момент подготовлено более 100 датасетов исследований лучевой диагностики. Это делается для того, чтобы убедиться, что ИИ-решение, обученное и протестированное разработчиком на конкретном наборе данных, сможет качественно работать в новых условиях.
Ошибки ИИ: кого винить в неверном диагнозе
Ежегодно из-за ошибок и непрофессионализма врачей в России умирает 70 тыс. человек. В Америке — это каждая третья смерть. В России нет сложившейся практики возложения вины на врача за неправильный диагноз. Использование ИИ поднимает еще более серьезные вопросы относительно халатности, так как не самая лучшая медицина может стать даже хуже. Если ИИ причинит вред пациенту из-за неправильного диагноза, то кого привлекут к ответственности — разработчика алгоритма, клинику, врача-оператора алгоритма или госорган, разрешивший использовать алгоритм?
Пока ML-диагностика — это вспомогательное средство для принятия клинических решений, а не замена медицинской диагностики, поэтому ответственность за возможные ошибки несет врач.
На данный момент сложно понять, допустим, почему ИИ выдал именно такую рекомендацию, из-за непрозрачности работы алгоритмов машинного обучения. Сейчас они работают как «черные ящики» — многие алгоритмы являются конфиденциальной информацией разработчиков, как и наборы данных пациентов для обучения алгоритмов.
Препятствия для массового внедрения ML-решений
Кроме сложности сравнения и выбора инструментов машинного обучения есть ряд других проблем:
- Технологический барьер
Основная проблема — отсутствие больших датасетов с хорошими (чистыми и полными) данными. Также нет референсных датасетов, на которых можно было бы сравнивать точность работы алгоритмов разных вендоров. Пока таких датасетов нет, решения будут узкими (выявить аномалию на снимке — да; обобщить разные анализы и поставить диагноз — нет, это пока может только врач). Государственная политика может содействовать внедрению подобных решений через формирование датасетов и создание пилотных зон.
- Сложность интеграции
Эксперты прогнозируют сложную интеграцию ML-диагностики в уже сложившуюся практику сбора и обработки изображений в больницах. В России сейчас есть большое количество разных систем, и разработчикам ИИ-решений необходимо значительную часть ресурсов тратить на интеграционные мероприятия.
- Российская региональная специфика
Кроме сложности интеграции, многие регионы нашей страны пока не выражают активное желание провести пилотные испытания и внедрение ИИ-решений. В Москве организаторы эксперимента были готовы к тому, что все медицинские ML-продукты еще далеки от идеала и часто требуют значительной доработки, дообучения и калибровки. В регионах же научно-экспериментального интереса к ML-продуктам значительно меньше, там ждут законченных решений. К тому же скепсис и недоверие врачей к ИИ в регионах значительно выше. То есть успешно работать в регионах смогут только разработчики с клинически проверенными системами.
- Регистрационное удостоверение медицинского изделия
Продажа и эксплуатация ML-решений в сфере здравоохранения могут осуществляться только после получения регистрационного удостоверения медицинского изделия, выданного Росздравнадзором.
Евгений Никитин:
«Специфика медицинских продуктов на базе искусственного интеллекта связана с длинным циклом разработки до выхода на операционную окупаемость и высокий уровень затрат на подготовку и разметку медицинских данных. Как правило, сейчас компании привлекают только в первом инвестиционном раунде от ₽50 млн до ₽180 млн».
Прогнозирование рака
Несмотря на растущую зависимость диагностики рака от белковых биомаркеров и предвзятость в пользу обнаружения рака простаты и груди, машинное обучение обеспечивает значительное (на 15–25%) повышение точности прогнозирования предрасположенности к раку, рецидивов и смертности.
В 2019 году команда исследователей IBM опубликовала исследование новой ИИ-модели, которая может прогнозировать развитие злокачественного рака груди у пациенток в течение ближайшего года. Это первый алгоритм с учетом не только изображений, но и анамнеза здоровья пациентки. Модель правильно предсказала развитие рака груди в 87% случаев, а также правильно интерпретировала 77% незлокачественных образований.
Тренды прогнозирования рака:
- прогнозирование предрасположенности к раку (то есть оценка риска) — вероятность развития какого-либо типа рака до возникновения болезни;
- прогноз рецидива рака — вероятность повторного возникновения рака после видимого избавления от болезни;
- прогноз выживаемости — предсказать исход (продолжительность жизни, выживаемость, прогрессирование, чувствительность опухоли к лекарствам) после постановки диагноза.
Персонализированное лечение рака
Больные раком нуждаются в сложном индивидуальном комплексном лечении. Решения на основе искусственного интеллекта способны трансформировать не только диагностику, но и область лечения пациентов:
- Геномная характеристика опухолей
Методы искусственного интеллекта используются для идентификации генных мутаций по изображениям опухолей вместо использования традиционного геномного секвенирования. Например, исследователи из Нью-Йоркского университета использовали глубокое обучение для анализа изображений опухолей легкого и выяснили, что DL может не только точно различать два наиболее распространенных подтипа рака легкого, аденокарциному и плоскоклеточный рак, но и предсказывать мутировавшие гены по изображениям.
- Подбор персональной лекарственной терапии при помощи ИИ
Исследователи из Университета Аалто, Университета Хельсинки и Университета Турку в Финляндии разработали модель машинного обучения, которая точно предсказывает, как комбинации различных противораковых препаратов убивают различные типы раковых клеток. Сложная лекарственная терапия часто повышает эффективность лечения и может уменьшить вредные побочные эффекты, если дозировка отдельных лекарств уменьшена. С помощью машинного обучения можно подобрать лучшие комбинации для выборочного уничтожения раковых клеток с определенным генетическим или функциональным составом.
- Подбор персональных доз лучевой терапии при помощи ИИ
Лучевая терапия очень тяжело переносится организмом и трудно предсказать, как отреагируют пациенты. В 2019 году ИИ был успешно использован для планирования фокуса лучевой терапии и точно предсказал побочные эффекты от нее у пациентов с раком головы и шеи. Новая технология позволит врачам лучше планировать лучевую терапию с учетом особенностей каждого отдельного человека.
- Прогнозирование результатов иммунотерапии
Согласно исследованию, алгоритм ИИ может успешно находить ранее невидимые изменения в паттернах изображений компьютерной томографии и определять, какую пользу от иммунотерапии получат пациенты с раком легкого. Иммунотерапия — дорогостоящее лечение, но в настоящее время только около 20% больных раком действительно получают от нее пользу.