




Об авторе: Сергей Лукашкин, директор научно-образовательного центра «Цифровые технологии в образовании» ВШМ СПбГУ.
Что такое SLM
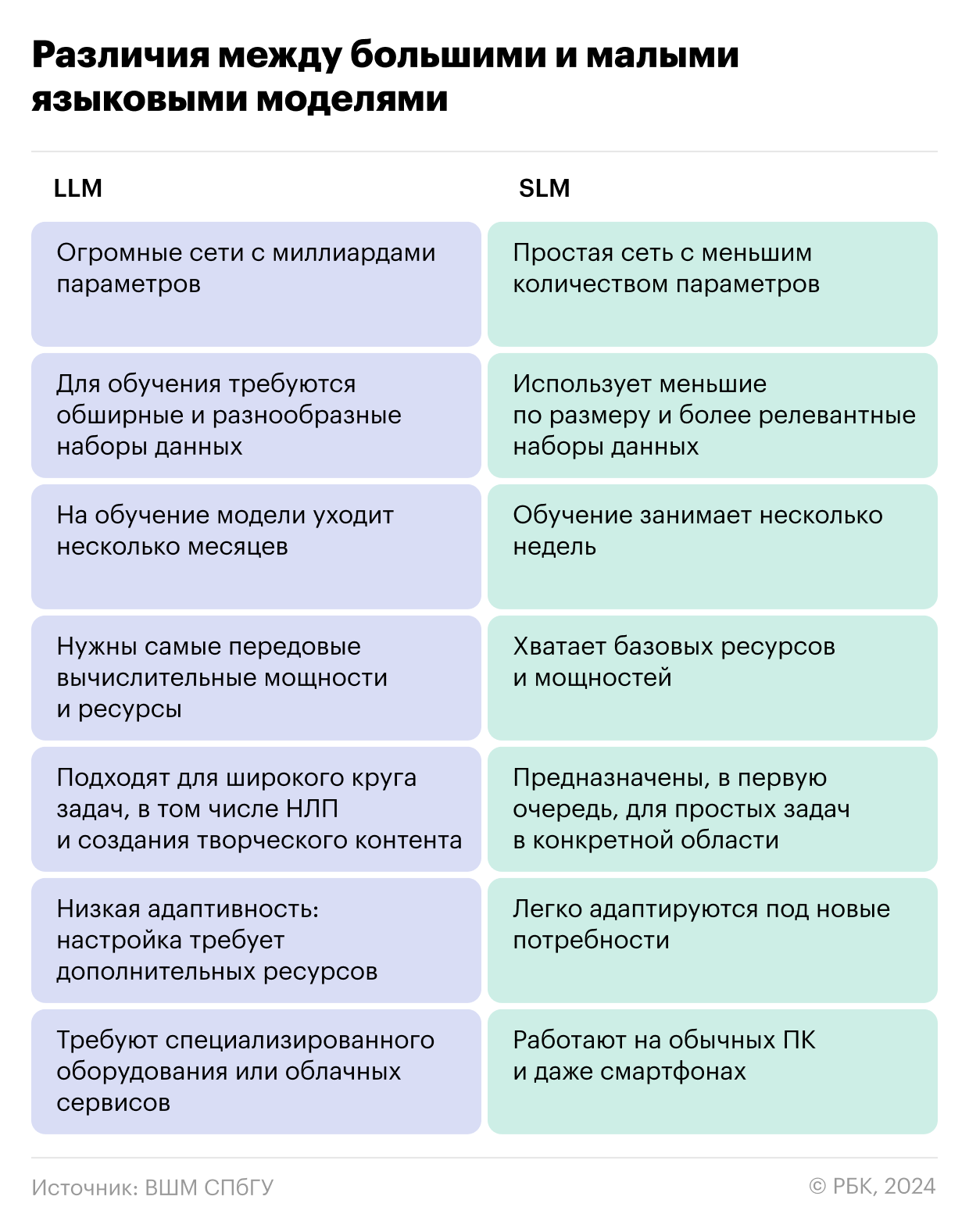
Малые языковые модели (Small Language Models или SLM), в отличие от больших языковых моделей (LLM), обученных на огромных массивах данных, используют небольшие объемы, но лучшего качества, поэтому работают точнее.
Четкого разделения между LLM и SLM пока что нет. Одни относят к большим языковым моделям те, что работают со 100 млн и более параметров, а к малым — от 1 до 10 млн. Другие называют цифры в 100+ млрд и 10 млрд соответственно. Но речь идет не только о числе параметров, но и объеме данных, физических размерах и нейронной архитектуре. Если упростить, то малая языковая модель — это та, что требует в разы меньше ресурсов при обучении и анализе данных, чем большая.

Как они работают
В отличие от универсальных LLM, малые модели предназначены для решения узкоспециализированных задач, с которыми справляются заметно лучше. Чтобы извлечь максимум из меньшего набора данных, в SLM используют разные методы:
- Дистилляция: когда данные от предварительно обученной LLM передаются к малой модели.
- Обрезка и квантование: когда сокращают объемы представления параметров с 32 до 8 или даже 2 бит, уменьшая размеры и требования к ресурсам, а также количество ошибок.
- Более эффективные архитектуры: исследователи постоянно разрабатывают новые нейронные архитектуры, предназначенные специально для SLM, чтобы оптимизировать их работу.
Чтобы научить малую модель «думать» так же хорошо, как большая, разработчики настраивают малые модели специальным образом. В итоге SLM не слепо копируют поведение LLM, а выбирают другие стратегии решения задач. Например, отвечая на объемный вопрос, они сначала разбивают его на части и решают пошагово, а не целиком. Это помогает экономить ресурсы и получать такие же точные результаты.
В чем главные плюсы
Исследования показывают, что у SLM перед LLM по крайней мере несколько важных преимуществ:
-
Экономичность. Обучение LLM требует колоссальных затрат: на одну модель уходит в среднем от $9 млн до 23 млн, а модели вроде GPT-3 расходуют до 1,3 тыс. МВт/ч — это как если бы вы смотрели Netflix 1,6 млн часов. В основе больших моделей — архитектура Transformer, которая по мере увеличения данных требует все больше памяти и вычислительных мощностей.
SLM потребляют гораздо меньше памяти и других ресурсов, что делает их более доступными. К примеру, чтобы обучить PaLM от Google, потребовалось больше 6 тыс. супермощных чипов TPU v4, тогда как для обучения малой модели OPT от Meta AI (принадлежит корпорации Meta — признана в России экстремистской и запрещена) понадобилось всего 992 графических процессора Nvidia A100 по 80 Гб каждый. Для малых моделей достаточно оперативной памяти в 16 Гб или меньше, если речь идет о мобильных версиях.
-
Точность. Меньшие объемы данных и параметров у SLM не приводят к потере качества. Этому способствует тщательный отбор данных: среди них нет источников, которые ввели бы нейросеть в заблуждение. Например, недавно выпущенная модель Stable LM 2 c 1,6 млрд параметров обошла по эффективности в MT Bench алгоритм Falcon-40B, который в 25 раз больше.
-
Безопасность. За счет меньшего объема данных в SLM «мишеней» для хакерских атак тоже меньше, поэтому риски взлома и утечки данных тоже гораздо ниже. Данные максимально фильтруют от нерелевантного и некачественного контента, добиваясь меньшего объема. В результате снижаются риски неэтичного или вредоносного использования.
-
Доступность данных. Если вы не Google или Microsoft, собрать огромные массивы данных будет сложно и очень дорого. Особенно если учесть, что многие данные из Сети содержат чувствительную информацию или защищены авторским правом — например, научные исследования или книги. А значит, возникают еще и юридические тонкости. В случае с SLM на очистку прав требуется гораздо меньше ресурсов, а риски нарушений сводятся к нулю.
В LLM массивы данных огромны, но распределены неравномерно: например, огромную долю составляют материалы на английском. В SLM за счет более качественного отбора можно получить данные на разных языках, чтобы результаты были точнее и объективнее.
-
Простота и удобство. С малыми моделями проще работать как техническим специалистам, так и обычным пользователям. В отличие от LLM, их можно разворачивать даже на обычных ПК или смартфонах, моментально настраивая и изменяя для конкретных задач.
-
Скорость. Благодаря небольшим объемам SLM выдают результат гораздо быстрее, что особенно важно там, где нужны аналитика и прогнозы в режиме онлайн.
-
Прозрачность. Более простая архитектура и меньший объем данных позволяют лучше понимать, как работает конкретная модель, и предсказывать результаты.
Какие SLM есть на рынке
Основные разработки принадлежат тем же компаниям, которые уже выпустили LLM:
- GPT-Neo и GPT-J — это уменьшенные версии моделей GPT от OpenAI со 125 млн и 6 млрд параметров соответственно, которые достаточно универсальны и при этом работают с ограниченными вычислительными ресурсами.
- DistilBERT, BERT Mini, Small, Medium и Tiny — мини-версии большой модели BERT для обработки естественного языка (NLP) с разным количеством параметров: от 4,4 до 41 млн (у большой модели их от 110 до 340 млн). Есть также MobileBERT, разработанная для мобильных устройств.
- Orca 2 — малая модель от Microsoft, которая базируется на большой Orca с 13 млрд параметров, но с оптимизированными и улучшенными данными, а также тонкой настройкой Llama 2.
- Phi 3 — еще одна разработка Microsoft с 3,8 млрд параметров, которая легко адаптируется для развертывания как в облаке, так и на локальных ресурсах. По словам разработчиков, ее сильные стороны — точное понимание языка и контекста, логичность рассуждений и математические методы анализа.
- T5-Small — модель на базе Text-to-Text Transfer Transformer (T5) от Google.
- RecurrentGemma — еще одна SLM от Google с 2,2 млрд параметров, которая генерирует текст в режиме онлайн на устройствах с ограниченными ресурсами, включая смартфоны, ПК и IoT.

Каковы перспективы малых моделей
Хотя пока малые модели отстают от больших в технической части, за счет экономичности и безопасности они будут пользоваться спросом, а значит, активно развиваться.
В отличие от LLM, у SLM больше шансов стать массовыми и найти применение, в том числе, в системах интернета вещей: в рамках «умного» дома, транспорта или цифровых двойников предприятий. Для последних решающий фактор — большая прозрачность и безопасность, так как на крупных производствах и внутри корпораций действуют жесткие требования конфиденциальности и защиты данных.
В ближайшей перспективе SLM станут доступны на большинстве смартфонов. В числе первых — Gemini Nano от Google, первая малая модель для смартфонов на базе Android, которая уже есть в Pixel 8 Pro. Apple, в свою очередь, выпустила OpenELM, состоящую из 8 малых моделей от 270 млн до 3 млрд параметров, которые предназначены для смартфонов на iOS. В компании также заявили о планах внедрить модели на базе генеративного ИИ в новые версии iOS в качестве базовых инструментов.
Если говорить про конкретные задачи, то SLM могут идеально справляться там, где нужно «схватывать на лету»: додумывать задачу по первым словам, дописывать текст, переводить и исправлять ошибки прямо в процессе написания. Например, для синхронного перевода или генерации субтитров на смартфоне.
Как и с LLM, одна из самых перспективных — работа SLM с RAG (Advanced Retrieval-Augmented Generation). Это метод обучения, при котором к ответу нейросети добавляют дополнительные данные из внешних источников, чтобы она ответила более полно и точно. Например, когда пользователь спрашивает про курс доллара, а нейросеть воспринимает это абстрактно. Тогда в ее ответ можно добавить курс доллара на данный момент.
Еще одна перспективная сфера для малых моделей — персональные ИИ-ассистенты. Они уже появляются в виде мобильных устройств без привычных нам интерфейсов (а иногда даже без экрана) и умеют делать почти все: от заказа столика в ресторане до управления «умным» домом. Для бизнеса они могут составлять письма и сообщения, следить за качеством обслуживания клиентов и эффективностью сотрудников.