





Что такое машинное обучение?
Единого определения для machine learning (машинного обучения) пока нет. Но большинство исследователей формулируют его примерно так:
Машинное обучение — это наука о том, как заставить ИИ учиться и действовать как человек, а также сделать так, чтобы он сам постоянно улучшал свое обучение и способности на основе предоставленных нами данных о реальном мире.
Вот как определяют машинное обучение представители ведущих ИТ-компаний и исследовательских центров:
Nvidia: «Это практика использования алгоритмов для анализа данных, изучения их и последующего определения или предсказания чего-либо».
Университет Стэнфорда: «Это наука о том, как заставить компьютеры работать без явного программирования».
McKinsey & Co: «Машинное обучение основано на алгоритмах, которые могут учиться на данных, не полагаясь на программирование на основе базовых правил».
Вашингтонский университет: «Алгоритмы машинного обучения могут сами понять, как выполнять важные задачи, обобщая примеры, которые у них есть».
Университет Карнеги Меллон: «Сфера машинного обучения пытается ответить на вопрос: «Как мы можем создавать компьютерные системы, которые автоматически улучшаются по мере накопления опыта и каковы фундаментальные законы, которые управляют всеми процессами обучения?»
История машинного обучения
Дмитрий Ветров, профессор-исследователь, заведующий Центром глубинного обучения и байесовских методов Факультета компьютерных наук ВШЭ, отмечает: изначально компьютеры использовались для задач, алгоритм решения которых был известен человеку. И только в последние годы пришло понимание, что они могут находить способ решать задачи, для которых алгоритма решения нет или он не известен человеку. Так появился искусственный интеллект в широком смысле и технологии машинного обучения в частности.
- Первый компьютер с прототипом ИИ появился в 1946 году — в рамках ЭНИАК, сверхсекретного проекта армии США. Его можно было использовать для электронных вычислений и многих других задач;
- В 1950 году появился тест Алана Тьюринга для оценки интеллекта компьютера. С его помощью ученый предлагал определить, способен ли компьютер мыслить как человек;
- В 1958 году американский нейрофизиолог Фрэнк Розенблатт придумал Персептрон — первую искусственную нейронную сеть, а также первый нейрокомпьютер «Марк-1»;
- В 1959 году американский исследователь ИИ Марвин Минский создал SNARC — первую вычислительную машину на базе нейросети;
- В том же году его коллега Артур Самуэль изобрел первую программу по игре в шашки, которая обучалась самостоятельно. Он впервые ввел термин «машинное обучение», описав его как процесс, в результате которого машина показывает поведение, на которое не была изначально запрограммирована;
- В 1967 году был создан первый метрический алгоритм для классификации данных, который позволял ИИ использовать шаблоны для распознавания и обучения;
- В 1997 году программа Deep Blue впервые обыграла чемпиона мира по шахматам Гарри Каспарова;
- В 2006 году исследователь нейросетей Джеффри Хинтон ввел термин «глубокое обучение» (deep learning);
- В 2011 году была основана Google Brain — подразделение Google, которое занимается проектами в области ИИ;
- В 2012 году в рамках другого подразделения — Google X Lab — разработали нейросетевой алгоритм для распознавания котов на фото и видео. Тогда же Google запустила облачный сервис Google Prediction API для машинного обучения, который анализирует неструктурированные данные;
- В 2014 году Facebook (с 21 марта 2022 года соцсеть запрещена в России решением суда) разработала нейросеть DeepFace для распознавания лиц на фото и видео. Ее алгоритм работает с точностью 97%;
- В 2015 году Amazon запустила Amazon Machine Learning — платформу машинного обучения, несколько месяцев спустя аналогичная появилась и у Microsoft: Distributed Learning Machine Toolkit.
Как связаны машинное и глубокое обучение, ИИ и нейросети
Машинное обучение — это одна из областей искусственного интеллекта (ИИ).
Нейросети — один из видов машинного обучения.
Глубокое обучение — это один из видов архитектуры нейросетей.

Глубокое обучение также включает в себя исследование и разработку алгоритмов для машинного обучения. В частности — обучения правильному представлению данных на нескольких уровнях абстракции. Системы глубокого обучения за последние десять лет добились особенных успехов в таких областях как обнаружение и распознавание объектов, преобразование текста в речь, поиск информации.
Какие задачи решает машинное обучение?
С помощью машинного обучения ИИ может анализировать данные, запоминать информацию, строить прогнозы, воспроизводить готовые модели и выбирать наиболее подходящий вариант из предложенных.
Особенно полезны такие системы там, где необходимо выполнять огромные объемы вычислений: например, банковский скоринг (расчет кредитного рейтинга), аналитика в области маркетинговых и статистических исследований, бизнес-планирование, демографические исследования, инвестиции, поиск фейковых новостей и мошеннических сайтов.
В Леруа Мерлен используют Big Data и Machine Learning, чтобы находить остатки товара на складах.
В маркетинге и электронной коммерции машинное обучение помогает настроить сервисы и приложения так, чтобы они выдавали персональные рекомендации.
Стриминговый сервис Spotify с помощью машинного обучения составляет для каждого пользователя персональные подборки треков на основе того, какую музыку он слушает.
Сегодня ключевые исследования сфокусированы на разработке машинного обучения с эффективным использованием данных — то есть систем глубокого обучения, которые могут обучаться более эффективно, с той же производительностью, за меньшее время и с меньшими объемами данных. Такие системы востребованы в персонализированном здравоохранении, обучении роботов с подкреплением, анализе эмоций.
Китайский производитель «умных» пылесосов Ecovacs Robotics обучил свои пылесосы распознавать носки, провода и другие посторонние предметы на полу с помощью множества фотографий и машинного обучения.
«Умная» камера на базе микрокомпьютера Raspberry Pi 3B+ с помощью фреймворка TensorFlow Light научилась распознавать улыбку и делать снимок ровно в этот момент, а также — выполнять голосовые команды.
В сфере инвестиций алгоритмы на базе машинного обучения анализируют рынок, отслеживают новости и подбирают активы, которые выгоднее всего покупать именно сейчас. При этом с помощью предикативной аналитики система может предсказать, как будет меняться стоимость тех или иных акций за конкретный период и корректирует свои данные после каждого важного события в отрасли.
Согласно исследованию BarclayHedge, более 50% хедж-фондов используют ИИ и машинное обучение для принятия инвестиционных решений, а две трети — для генерации торговых идей и оптимизации портфелей.
Наконец, машинное обучение способствует настоящим прорывам в науке.
Нейросеть AlphaFold от DeepMind в 2020 году смогла расшифровать механизм сворачивания белка. Над этой задачей ученые-биологи бились больше 50 лет.
Как устроено машинное обучение
По словам Дмитрия Ветрова, процесс машинного обучения выглядит следующим образом.
Есть большое число однотипных задач, в которых известны условие и правильный ответ или один из возможных ответов. Например, машинный перевод, где условие — фраза на одном языке, а правильный ответ — ее перевод на другой язык.
Модель машинного обучения, например, глубинная нейронная сеть, работает по принципу «черного ящика», который принимает на вход условие задачи, а на выходе выдает произвольный ответ. Например, какой-либо текст на втором языке.
У «черного ящика» есть дополнительные параметры, которые влияют на то, как будет обрабатываться входной сигнал. Процесс обучения нейросети заключается в поиске таких значений параметров, при которых она будет выдавать ответ, максимально близкий к правильному. Когда мы настроим параметры нужным образом, нейросеть сможет правильно (или максимально близко к этому) решать и другие задачи того же типа — даже если никогда не знала ответов к ним.
Чтобы решать задачи, нейросетям нужны:
- Данные — примеры решений и всё, что может помочь в процессе обучения: статистика, примеры текстов, расчеты, показатели, исторические события. Данные собирают годами и объединяют в огромные массивы — датасеты, которые есть у всех ИТ-корпораций. Примером сбора является капча, которая просит вас выбрать все фото с автомобилями и запоминает правильные ответы;
- Признаки — они же свойства или характеристики. Это то, на что должна обратить внимание машина в процессе обучения. Например, цена акций, изображение животного, частотность слов или пол человека. Чем меньше признаков и чем четче они обозначены и оформлены, тем проще обучаться. Однако для сложных задач современным моделям приходится учитывать десятки миллионов параметров, определяющих, как входы преобразуются в выходы;
- Алгоритмы — это способ решения задачи. Для одной и той же задачи их может быть множество и важно выбрать самый точный и эффективный.
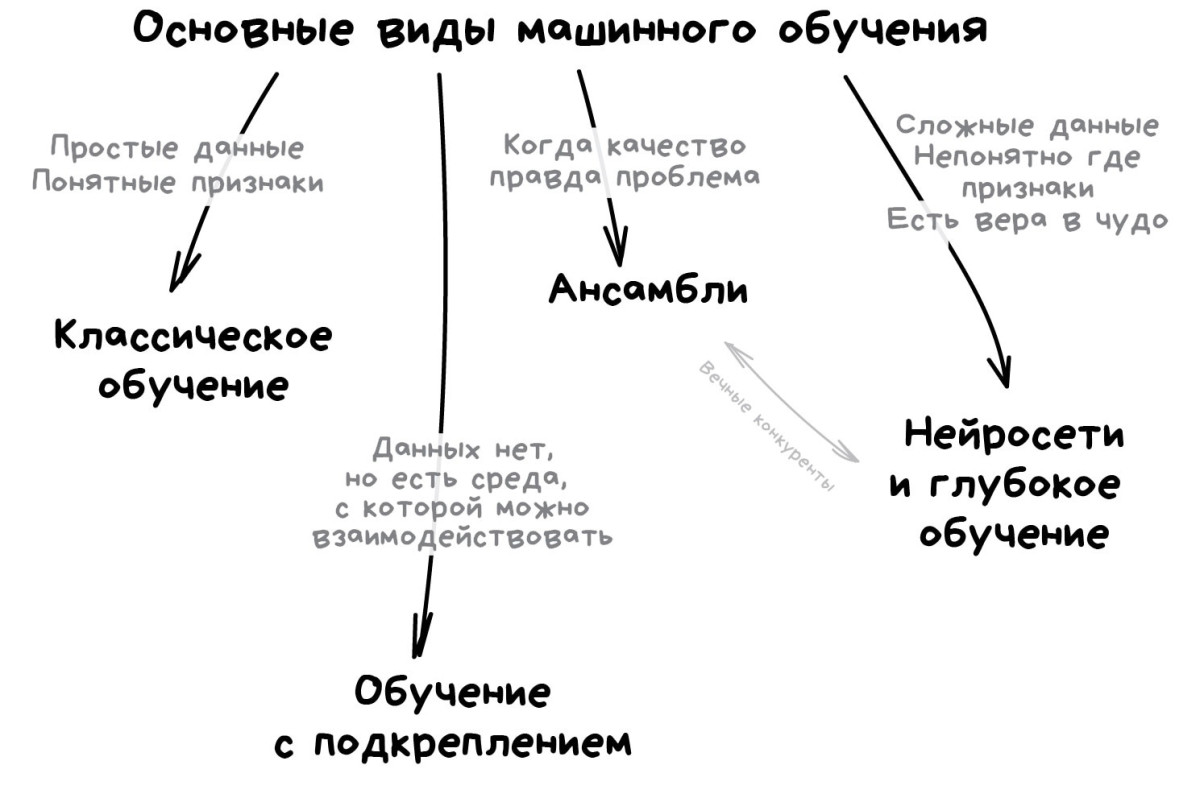
Основные виды машинного обучения
1. Классическое обучение
Это простейшие алгоритмы, которые являются прямыми наследниками вычислительных машин 1950-х годов. Они изначально решали формальные задачи — такие, как поиск закономерностей в расчетах и вычисление траектории объектов. Сегодня алгоритмы на базе классического обучения — самые распространенные. Именно они формируют блок рекомендаций на многих платформах.

Но классическое обучение тоже бывает разным:
Обучение с учителем — когда у машины есть некий учитель, который знает, какой ответ правильный. Это значит, что исходные данные уже размечены (отсортированы) нужным образом, и машине остается лишь определить объект с нужным признаком или вычислить результат.
Такие модели используют в спам-фильтрах, распознавании языков и рукописного текста, выявлении мошеннических операций, расчете финансовых показателей, скоринге при выдаче кредита. В медицинской диагностике классификация помогает выявлять аномалии — то есть возможные признаки заболеваний на снимках пациентов.
Обучение без учителя — когда машина сама должна найти среди хаотичных данных верное решение и отсортировать объекты по неизвестным признакам. Например, определить, где на фото собака.
Эта модель возникла в 1990-х годах и на практике используется гораздо реже. Ее применяют для данных, которые просто невозможно разметить из-за их колоссального объема. Такие алгоритмы применяют для риск-менеджмента, сжатия изображений, объединения близких точек на карте, сегментации рынка, прогноза акций и распродаж в ретейле, мерчендайзинга. По такому принципу работает алгоритм iPhoto, который находит на фотографиях лица (не зная, чьи они) и объединяет их в альбомы.
2. Обучение с подкреплением
Это более сложный вид обучения, где ИИ нужно не просто анализировать данные, а действовать самостоятельно в реальной среде — будь то улица, дом или видеоигра. Задача робота — свести ошибки к минимуму, за что он получает возможность продолжать работу без препятствий и сбоев.
Обучение с подкреплением инженеры используют для беспилотников, роботов-пылесосов, торговли на фондовом рынке, управления ресурсами компании. Именно так алгоритму AlphaGo удалось обыграть чемпиона по игре Го: просчитать все возможные комбинации, как в шахматах, здесь было невозможно.
3. Ансамбли
Это группы алгоритмов, которые используют сразу несколько методов машинного обучения и исправляют ошибки друг друга. Их получают тремя способами:
- Стекинг — когда разные алгоритмы обучают по отдельности, а потом передают их результаты на вход последнему, который и принимает решение;
- Беггинг — когда один алгоритм многократно обучают на случайных выборках, а потом усредняют ответы;
- Бустинг — когда алгоритмы обучают последовательно, при этом каждый обращает особое внимание на ошибки предыдущего.
Ансамбли работают в поисковых системах, компьютерном зрении, распознавании лиц и других объектов.
4. Нейросети и глубокое обучение
Самый сложный уровень обучения ИИ. Нейросети моделируют работу человеческого мозга, который состоит из нейронов, постоянно формирующих между собой новые связи. Очень условно можно определить их как сеть со множеством входов и одним выходом. Нейроны образуют слои, через которые последовательно проходит сигнал. Все это соединено нейронными связями — каналами, по которым передаются данные. У каждого канала свой «вес» — параметр, который влияет на данные, которые он передает.
ИИ собирает данные со всех входов, оценивая их вес по заданным параметрами, затем выполняет нужное действие и выдает результат. Сначала он получается случайным, но затем через множество циклов становится все более точным. Хорошо обученная нейросеть работает, как обычный алгоритм или точнее.
Настоящим прорывом в этой области стало глубокое обучение, которое обучает нейросети на нескольких уровнях абстракций.
Здесь используют две главных архитектуры:
- Сверточные нейросети первыми научились распознавать неразмеченные изображения — самые сложные объекты для ИИ. Для этого они разбивают их на блоки, определяют в каждом доминирующие линии и сравнивают с другими изображениями нужного объекта;
- Рекуррентные нейросети отвечают за распознавание текста и речи. Они выявляют в них последовательности и связывают каждую единицу — букву или звук — с остальными.
Нейросети с глубоким обучением требуют огромных массивов данных и технических ресурсов. Именно они лежат в основе машинного перевода, чат-ботов и голосовых помощников, создают музыку и дипфейки, обрабатывают фото и видео.
Проблемы машинного обучения
- Для того чтобы эффективно обучать нейросети и любые сложные алгоритмы, нужны огромные массивы данных и технические ресурсы: серверы, специальные помещения для них, высокоскоростной интернет без сбоев, много электроэнергии. На получение нужных данных уходят годы работы и миллионы долларов. Такие затраты может позволить себе только крупная ИТ-корпорация. Открытых датасетов совсем не много, некоторые можно купить, но стоят они очень дорого;
- С ростом мощностей для сбора и обработки датасетов растут и вредные выбросы, которые производят крупнейшие датацентры;
- Данные нужно не только собрать, но и разметить — так, чтобы машина точно определила, где какой объект и какие у него признаки. Это касается числовых данных, текстов, изображений. Опять же, чтобы сделать это вручную, нужны миллионные вложения. Например, у «Яндекса» есть «Яндекс.Толока» — сервис, где неразмеченные данные вручную обрабатывают миллионы фрилансеров. Такое тоже может себе позволить далеко не каждый разработчик;
- Даже если данных много и они регулярно обновляются, в процессе обучения может выясниться, что алгоритм не работает. Проблема может быть и в данных, и в самом подходе: когда машина успешно решила задачу с одними данными, но не в состоянии масштабировать решение с новыми условиями;
- Несмотря на все прорывы в глубоком обучении нейросетей, ИИ пока что не может создавать что-то абсолютно новое, выходить за рамки предложенных условий и превзойти заложенные в него способности. Другими словами, он пока что не в состоянии превзойти человека.
Перспективы машинного обучения: не начнет ли ИИ думать за нас?
Вопрос о том, не сделает ли машинное обучение ИИ умнее человека, изначально не совсем корректный. Дело в том, что в природе нет универсальной иерархии в плане интеллекта. Мы по умолчанию считаем себя умнее остальных существ, но, к примеру, белка способна запоминать местонахождения тысячи тайников с запасами, что не под силу даже очень умному человеку. А у осьминогов каждое щупальце способно мыслить и действовать самостоятельно.
Так же и с ИИ: он уже превосходит нас во всем, что касается сложных вычислений, но по-прежнему не способен сам ставить себе новые задачи и решать их, подбирая нужные данные и условия. Это ограничение в последние годы пытаются преодолеть в рамках сильного ИИ, но пока безуспешно. Надежду на решение этой проблемы внушают квантовые компьютеры, которые выходят за пределы обычных вычислений.
Зато мы в ближайшем будущем сможем заметно расширить свои возможности с помощью ИИ, передавая ему рутинные и затратные операции, общаясь и управляя техникой при помощи нейроинтерфейсов.
Что еще почитать про машинное обучение
- Статья о машинном обучении Педро Домингоса, почетного профессора компьютерных наук и инженерии Вашингтонского университета (англ.)
- Видеолекции о машинном обучении от профессора канадского Университета МакГилла (англ.).
- Статья в AI Magazine о вызовах и возможностях машинного обучения от ведущих исследователей (англ.)
- Исследователи и разработчики Facebook отвечают на самые актуальные вопросы о машинном обучении (англ.)
- Статья о перспективах и особенностях репрезентативного обучения (англ.)
- Цикл статей в рамках проекта Machine Learning for Humans (англ.)
- Статья о пяти самых актуальных алгоритмов с кластеризацией (способ сортировки данных в рамках классического обучения) (англ.)
- Лекции «Яндекса» о том, как работают рекомендательные сервисы.
- Хронология развития машинного обучения (англ.)
- Как выглядят разновидности нейросетей и чем они отличаются