




Осенью 2019 года разразился скандал с сервисом Apple Card: при регистрации в нем выдавались разные кредитные лимиты для мужчин и женщин. Даже Стиву Возняку не повезло:
За год до этого выяснилось, что платформа Netflix показывает пользователям разные постеры и тизеры — в зависимости от их пола, возраста и национальности. За это сервис обвинили в расизме.
Наконец, Марку Цукербергу регулярно достается за то, что Facebook якобы собирает, продает и манипулирует данными своих пользователей. В разные годы его обвиняли и даже судили за манипуляции во время американских выборов, пособничество российским спецслужбам, разжигание ненависти и радикальных взглядов, неуместную рекламу, утечку данных о пользователях, препятствия расследованиям против педофилов.
Запись в facebook пользователя zuck
При этом онлайн-сервис Pornhub ежегодно публикует отчеты о том, какое порно ищут люди разных национальностей, пола и возраста. И это почему-то никого не смущает. Хотя все эти истории похожи: в каждой из них мы имеем дело с большими данными, которые в XXI веке называют «новой нефтью».
Что такое большие данные
Большие данные — они же биг дата (англ. Big Data) или метаданные — это массив данных, которые поступают регулярно и в большом объеме. Их собирают, обрабатывают и анализируют, получая на выходе четкие модели и закономерности.
Яркий пример — это данные с Большого адронного коллайдера, которые поступают непрерывно и в большом количестве. С их помощью ученые решают множество задач.
Но большие данные в сети — это не только статистика для научных исследований. По ним можно проследить, как ведут себя пользователи разных групп и национальностей, на что обращают внимание и как взаимодействуют с контентом. Иногда для этого данные собирают не из одного источника, а из нескольких, сопоставляя и выявляя определенные закономерности.

О том, насколько важны большие данные в сети заговорили тогда, когда их стало действительно много. На начало 2020 года пользователей интернета в мире насчитывалось 4,5 млрд человек, из них 3,8 млрд зарегистрированы в соцсетях.
У кого есть доступ к Big Data
По данным опросов, больше половины россиян уверены, что их данные в сети используются третьими лицами. В то же время, многие размещают в соцсетях и приложениях личную информацию, фото и даже номер телефона.
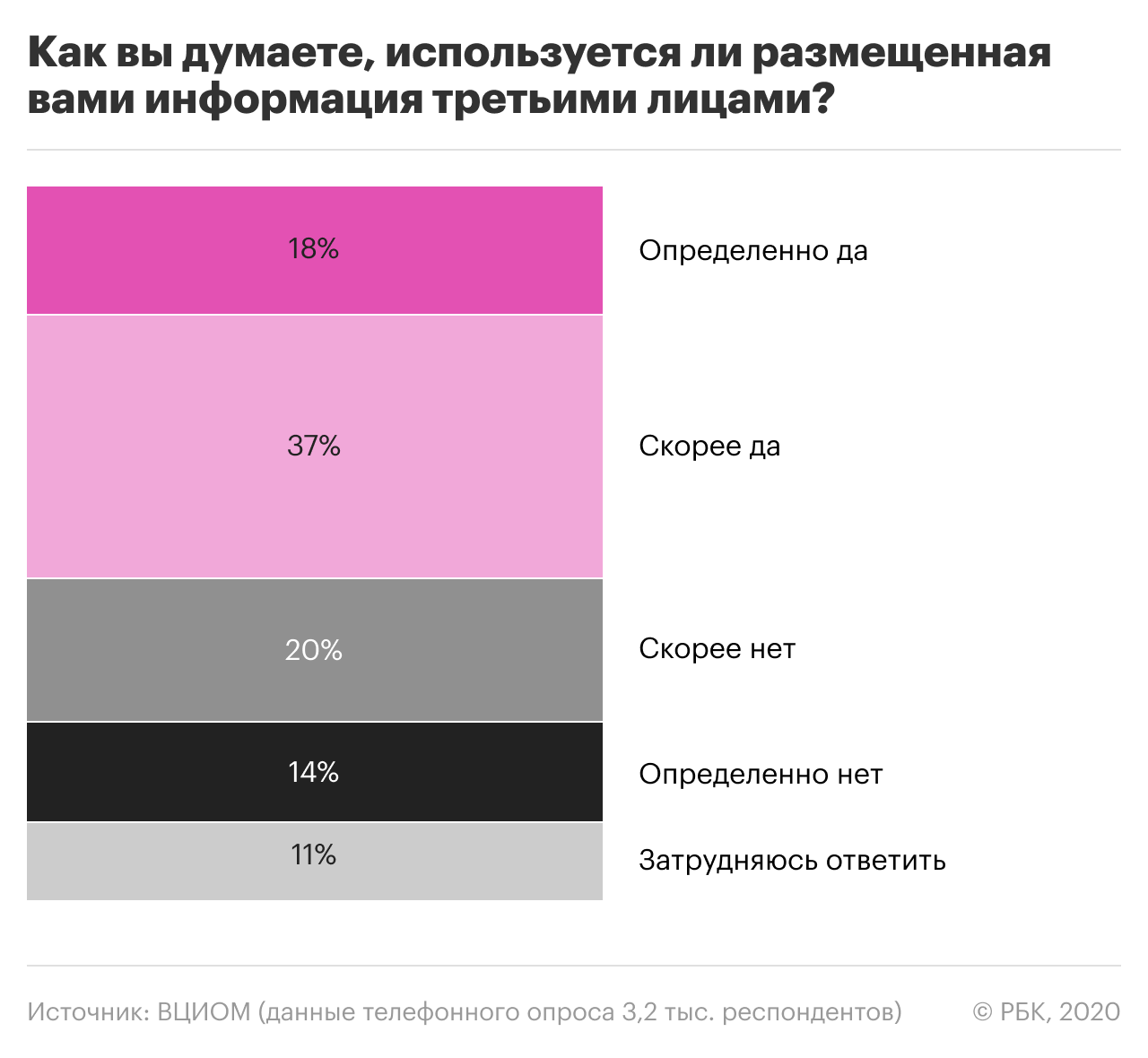
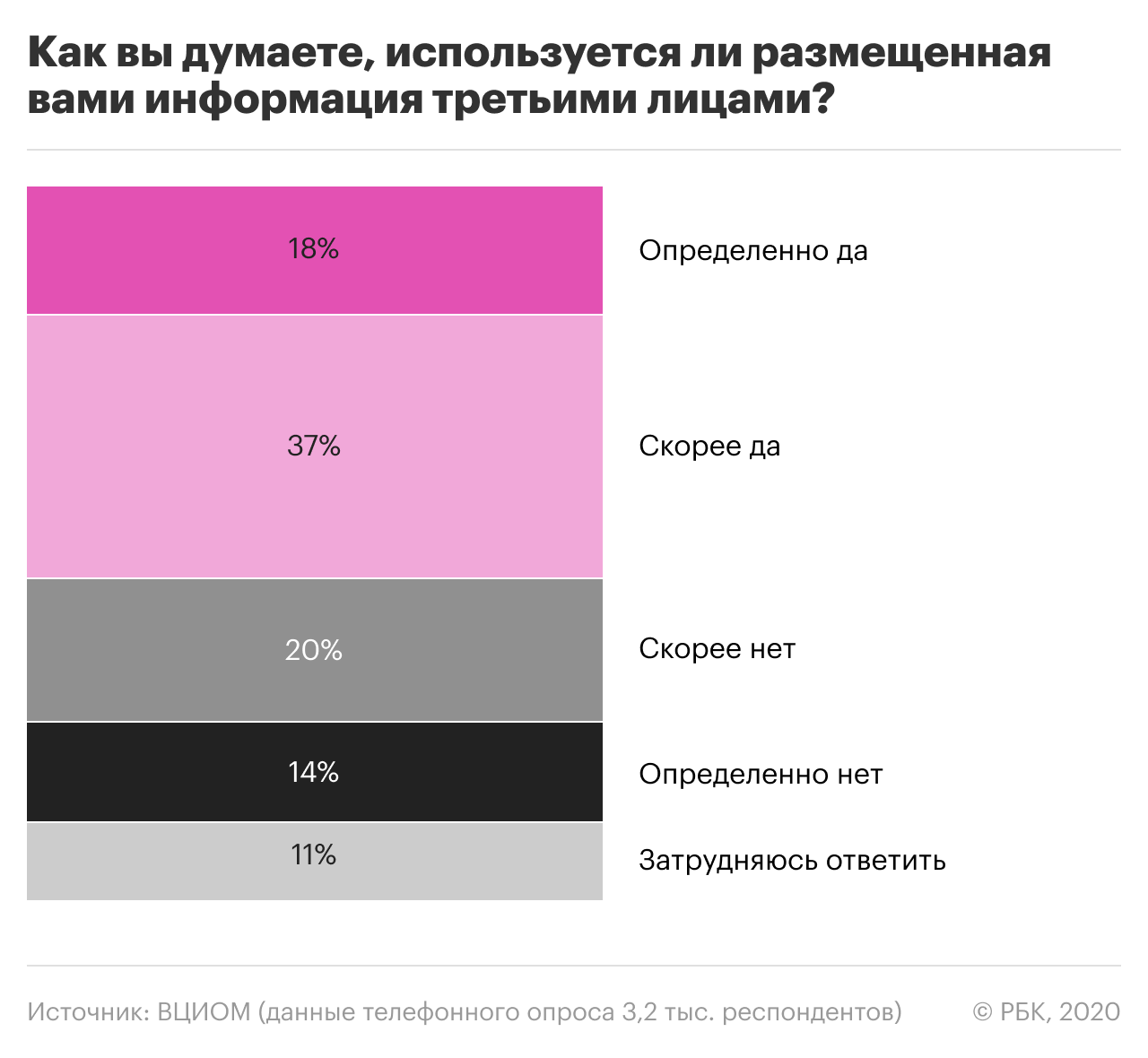
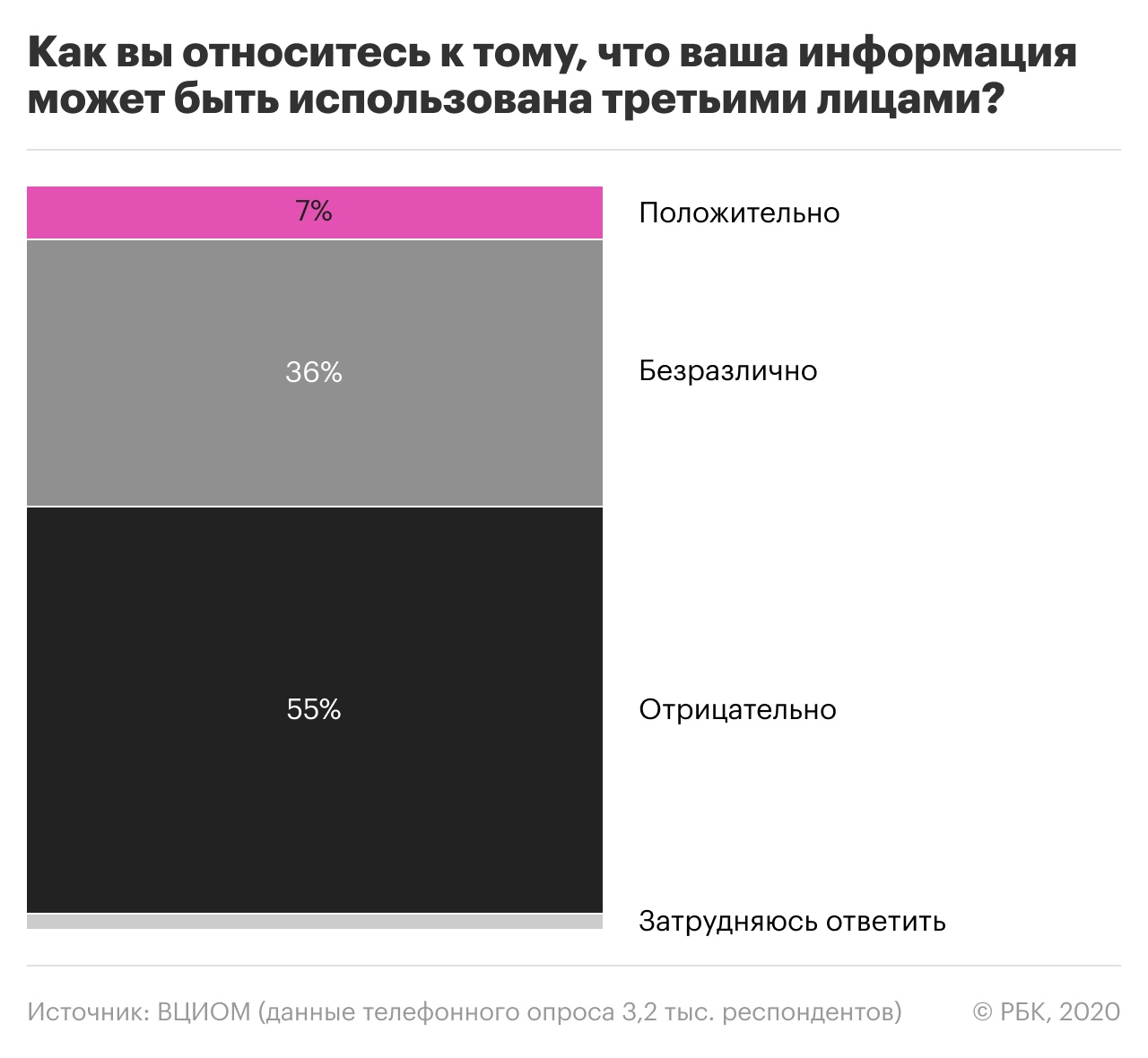
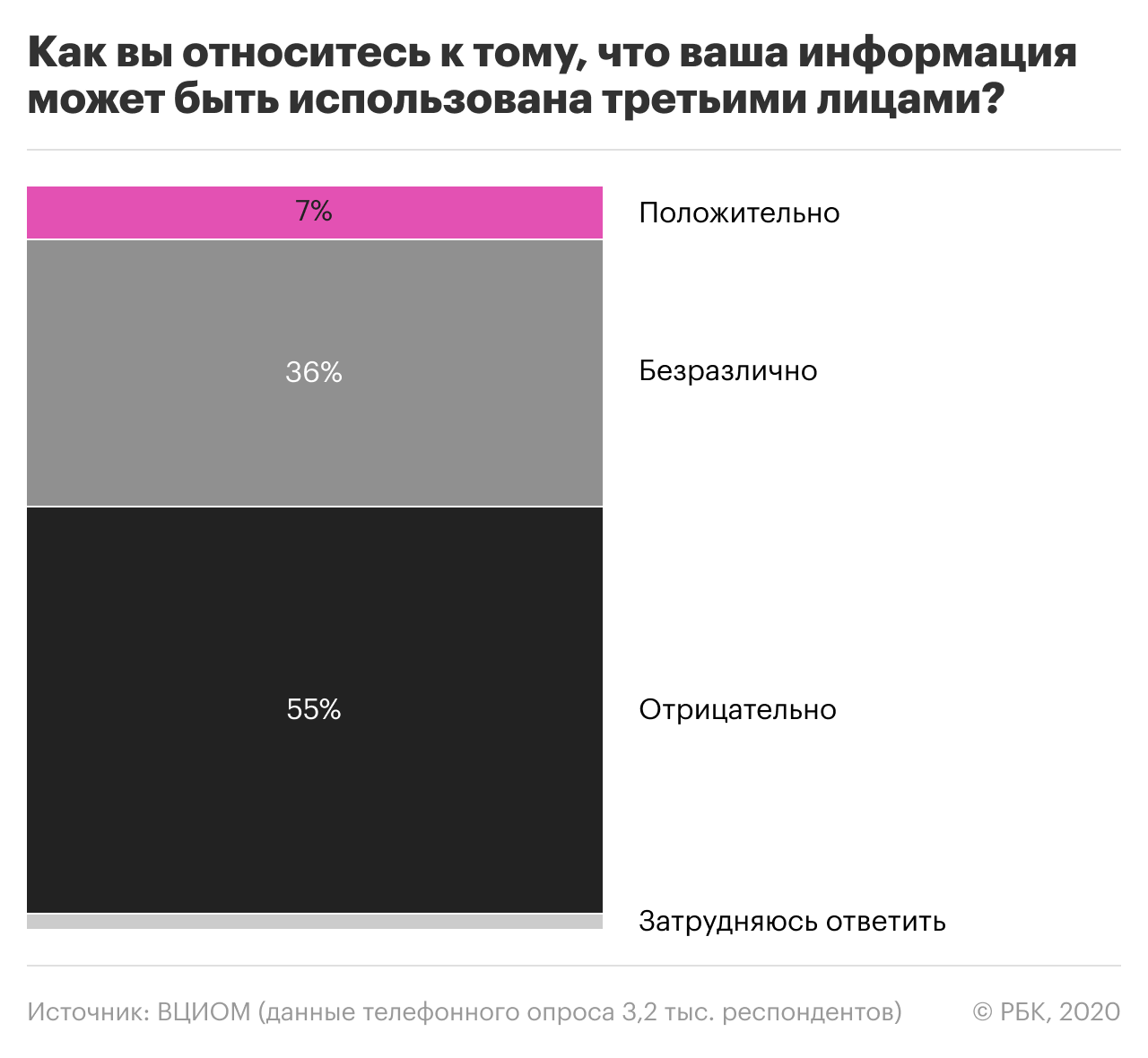
Здесь нужно пояснить: первое лицо — это сам пользователь, который размещает свои данные на каком-либо ресурсе или в приложении. При этом он дает согласие (ставит галочку в соглашении) на обработку этих данных вторым лицом — то есть владельцами ресурса. Третье лицо — это те, кому владельцы ресурса могут передать или продать данные пользователей. Часто это прописано в пользовательском соглашении, но не всегда.
В роли третьего лица выступают госорганы, хакеры или компании, которые покупают данные для коммерческих целей. Первые могут получить данные по решению суда или вышестоящей инстанции. Хакеры, понятно, никакими разрешениями не пользуются — они просто взламывают базы, хранящиеся на серверах. Компании (по закону) могут получить доступ к данным только в том случае, если вы сами им разрешили — поставив галку под соглашением. В противном случае это противозаконно.
Для чего компании используют Big Data?
Большие данные в коммерческой сфере использовали десятки лет, просто их поток не был таким интенсивным, как сейчас. Это, к примеру, записи с камер наблюдения, данные GPS-навигаторов или онлайн-платежи. Теперь, с развитием соцсетей, онлайн-сервисов и приложений все это можно связать и получить максимально полную картину: где живут потенциальные клиенты, что они любят смотреть, куда ездят в отпуск и какая у них марка машины.

Из примеров выше понятно, что с помощью больших данных компании, в первую очередь, хотят таргетировать рекламу. То есть предлагать продукты, услуги или отдельные опции только нужной аудитории и даже настраивать продукт под конкретного пользователя. К тому же, реклама в том же Facebook и на других крупных площадках становится все дороже, и показывать ее всем подряд совсем не выгодно.
Данные о потенциальных клиентах из открытых источников активно используют страховые компании, частные клиники и работодатели. Первые, к примеру, могут изменить условия страховки, если увидят, что вы часто ищете информацию по определенным заболеваниям или лекарствам, а работодатели — оценить, не склонны ли вы к конфликтам и асоциальному поведению.
Но есть и еще одна важная задача, над которой бьются в последние годы: подобраться к самой платежеспособной аудитории. Сделать это не так просто, хотя задачу заметно облегчают платежные сервисы и электронные чеки через единого ОФД (оператора фискальных данных). Чтобы подобраться как можно ближе, компании даже пытаются отследить и «воспитать» потенциальных клиентов с самого детства: через онлайн-игры, интерактивные игрушки и обучающие сервисы.
Как это устроено?
Самые большие возможности по сбору данных — у мировых корпораций, которые владеют сразу несколькими сервисами. У того же Facebook сейчас — более 2,5 млрд активных пользователей. При этом компания владеет и другими сервисами: Instagram — более 1 млрд, WhatsApp — более 2 млрд и другие.
Но еще большим влиянием обладает Google: почтой Gmail пользуется 1,5 млрд человек в мире, еще 2,5 млрд — мобильной ОС Android, больше 2 млрд — YouTube. И это не считая приложений Google-поиска и Google Maps, магазина Google Play и браузера Chrome. Осталось прикрутить свой онлайн-банк — и Google сможет знать о вас буквально все. Кстати, Яндекс в этом плане уже на шаг впереди, но он охватывает только русскоязычную аудиторию.
👍 В первую очередь компании интересует, что мы постим и лайкаем в соцсетях. К примеру, если банк видит, что вы женаты и активно лайкаете девушек в Instagram или Tinder, потребительский кредит вам, скорее, одобрят. А ипотеку на семью — уже нет.
Важно и то, на какую рекламу вы кликаете, как часто и с каким результатом.
📥 Cледующий шаг — это личные сообщения: в них информации гораздо больше. Утечки сообщений случались у ВКонтакте, Facebook, WhatsApp и других мессенджеров. По ним, к слову, легко отследить и геолокацию в момент отправки сообщения. Наверняка вы замечали: стоит с кем-то обсудить покупку чего-либо или просто заказ пиццы — в ленте тут же появляется релевантная реклама.
🚕 Большие данные активно используют и «сливают» сервисы доставки и такси. Они знают, где вы живете и работаете, что любите, какой у вас примерный доход. Uber, к примеру показывает цену выше, если вы едете из бара домой и явно перебрали. А когда у вас на телефоне куча других агрегаторов — наоборот, предложит подешевле.
🎞 Есть сервисы, которые используют фото и видео, чтобы собрать как можно больше информации. Например, библиотеки компьютерного зрения — такая есть у Google. Они сканируют вас и окружающее пространство, чтобы понять, какой у вас размер груди или рост, какие марки вы носите, на какой машине ездите, есть ли у вас дети и домашние животные.
💳 Те, кто предоставляет смс-шлюзы банкам для их рассылок, могут отследить ваши покупки по карте — зная 4 последние цифры и номер телефона — а потом продать эти данные кому-то еще. Отсюда весь этот спам со скидками и пиццей в подарок.
🤷♂️ Наконец, мы сами сливаем свои данные левым сервисам и приложениям. Вспомните этот хайп вокруг Getcontact, когда все радостно забивали свой номер телефона, чтобы узнать, как он записан у других. А теперь найдите их соглашение и почитайте, что там написано насчет передачи ваших данных (спойлер: владельцы могут передавать их третьим лицам на их усмотрение):
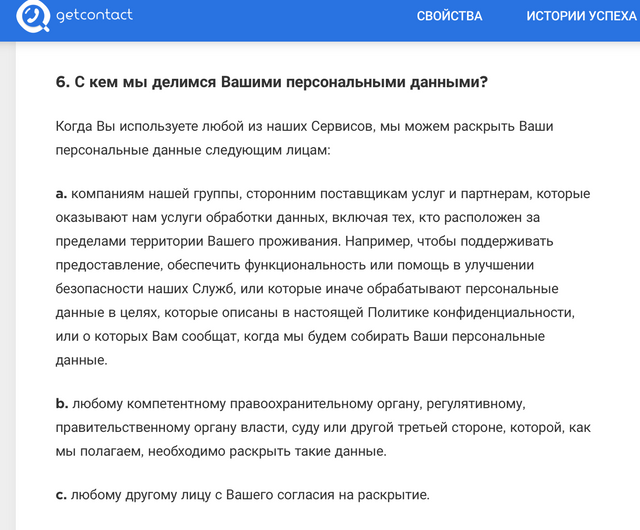
Корпорации могут годами успешно собирать и даже продавать данные пользователей, пока не дойдет до судебного иска — как это случилось с тем же Facebook. И то решающую роль сыграло нарушение компанией GDPR — закона в ЕС, который ограничивает использование данных гораздо жестче, чем американский. Еще один недавний пример — скандал с антивирусом Avast: один из дочерних сервисов компании собирал и продавал данные от 100 до 400 млн пользователей.
Но есть ли у всего этого хоть какие-то плюсы для нас?
Как большие данные помогают всем нам?
Да, есть и светлая сторона.
Большие данные помогают ловить преступников и предупреждать теракты, находить пропавших детей и защищать их от опасности.
С их помощью мы получаем крутые предложения от банков и персональные скидки. Благодаря им мы не платим за многие сервисы и соцсети, которые зарабатывают только на рекламе. Иначе один только Instagram обходился бы нам в несколько тысяч долларов в месяц.
В одном только Facebook — 2,4 млрд активных пользователей. При этом их прибыль за 2019 составила $18,5 млрд. Получается, что на каждом пользователе компания зарабатывает до $7,7 в год за счет рекламы.
Наконец, иногда это просто удобно: когда сервисы уже знают, где вы и что хотите, и вам не приходится самим искать нужную информацию.
Еще одна перспективная сфера для применения Big Data — образование.
В одном из американских вузов штата Вирджиния провели исследование, чтобы собрать данные о студентах так называемой группы риска. Это те, которые плохо учатся, пропускают занятия и вот-вот отчислятся. Дело в том, что в штатах каждый год отчисляются около 400 000 человек. Это плохо и для вузов, которым снижают рейтинг и урезают финансирование, и для самих студентов: многие берут кредиты на образование, которые после отчисления все равно придется выплачивать. Не говоря уже о потерянном времени и карьерных перспективах. С помощью больших данных можно вовремя вычислить отстающих и предложить им репетитора, дополнительные занятия и другую адресную помощь.
Такое, кстати, подойдет и для школ: тогда система будет оповещать учителей и родителей — мол, у ребенка проблемы, давайте вместе ему поможем. А еще Big Data поможет понять, какие учебники работают лучше и кто из учителей доступнее объясняет материал.
Еще один положительный пример — карьерное профилирование: это когда подросткам помогают определиться с будущей профессией. Здесь большие данные позволяют собрать ту информацию, которую невозможно добыть с помощью традиционных тестов: как ведет себя пользователь, на что обращает внимание, как взаимодействует с контентом.
В тех же США работает программа по профориентации — SC ACCELERATE. В ней, в том числе, используют технологию CareerChoice GPS: анализируют данные о характере учащихся, их склонностях к предметам, сильные и слабые стороны. Затем данные используют, чтобы помочь подросткам выбрать подходящие для них вузы.
Подписывайтесь и читайте нас в Яндекс.Дзене — технологии, инновации, эко-номика, образование и шеринг в одном канале.